Before analyzing clusters, we must define what constitutes a "functional match." Standard metrics often conflate specific terms with their broad parents. We adopted a probability-based approach to measure the specificity of the shared ancestor.
This ensures that we penalize vague matches (broad parents) and only reward specific functional concordance.
Engineering Contribution: To scale this evaluation to millions of protein homologs, I engineered a modularized CPU/GPU parallelization pipeline, optimizing the pairwise calculation.
1. The Problem: The Confidence Trap
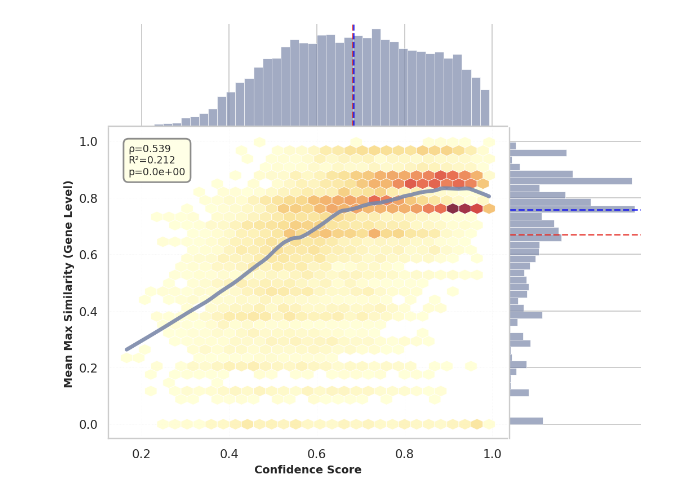
We benchmarked State-of-the-Art (SOTA) prediction models like DeepGOSE. Our analysis reveals a critical flaw: low prediction confidence directly correlates with low accuracy (Fig 1a).
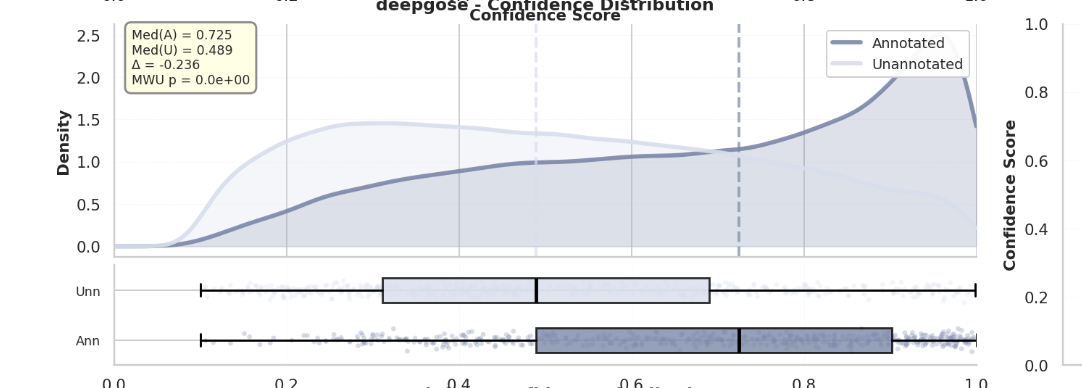
Furthermore, for unannotated genes ("Microbial Dark Matter"), these models exhibit extremely low confidence (Fig 1b). Effectively, SOTA models fail exactly where they are needed most.
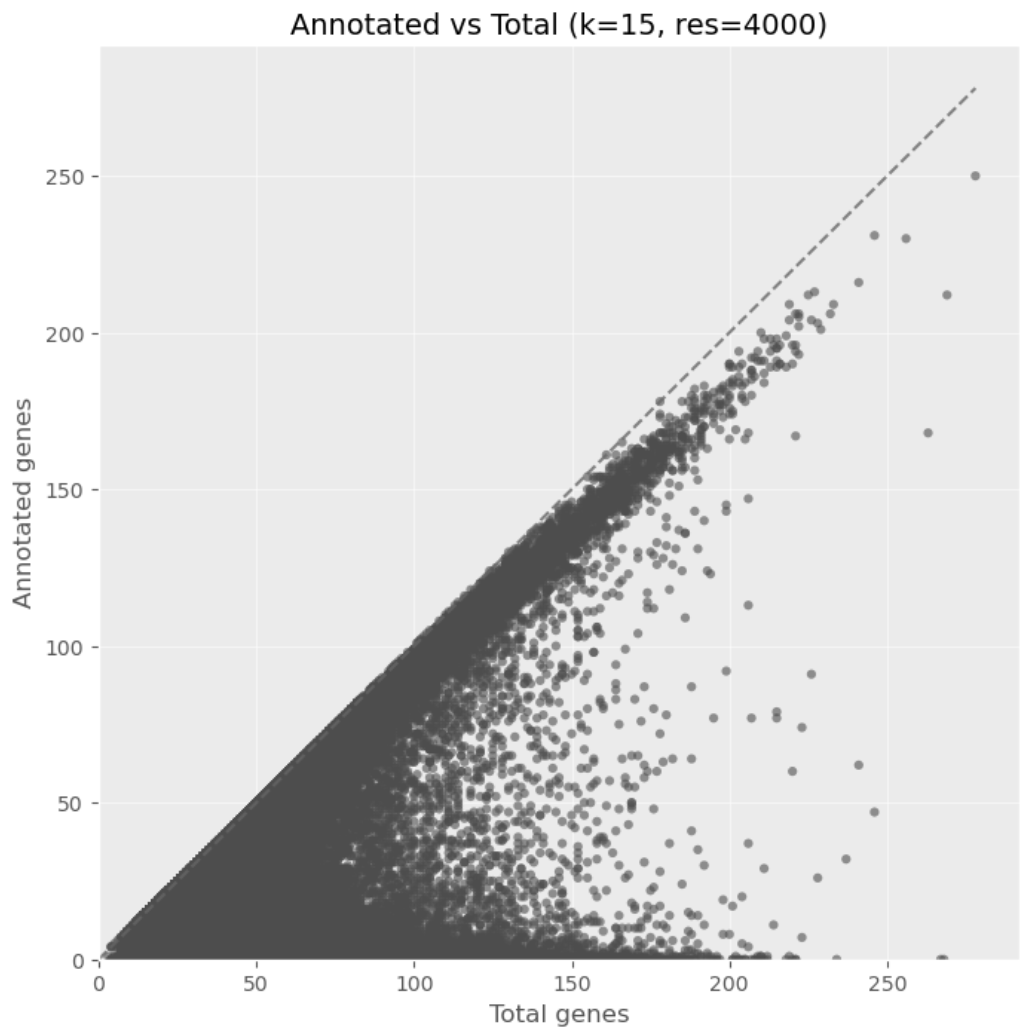
Critically, we observe a distinct separation (Fig 1c): clusters tend to be either fully annotated or fully unannotated. The scarcity of "mixed" clusters suggests that "Dark Matter" proteins form coherent, independent functional groups rather than being randomly scattered among known families.
2. The Solution: Beyond Structure
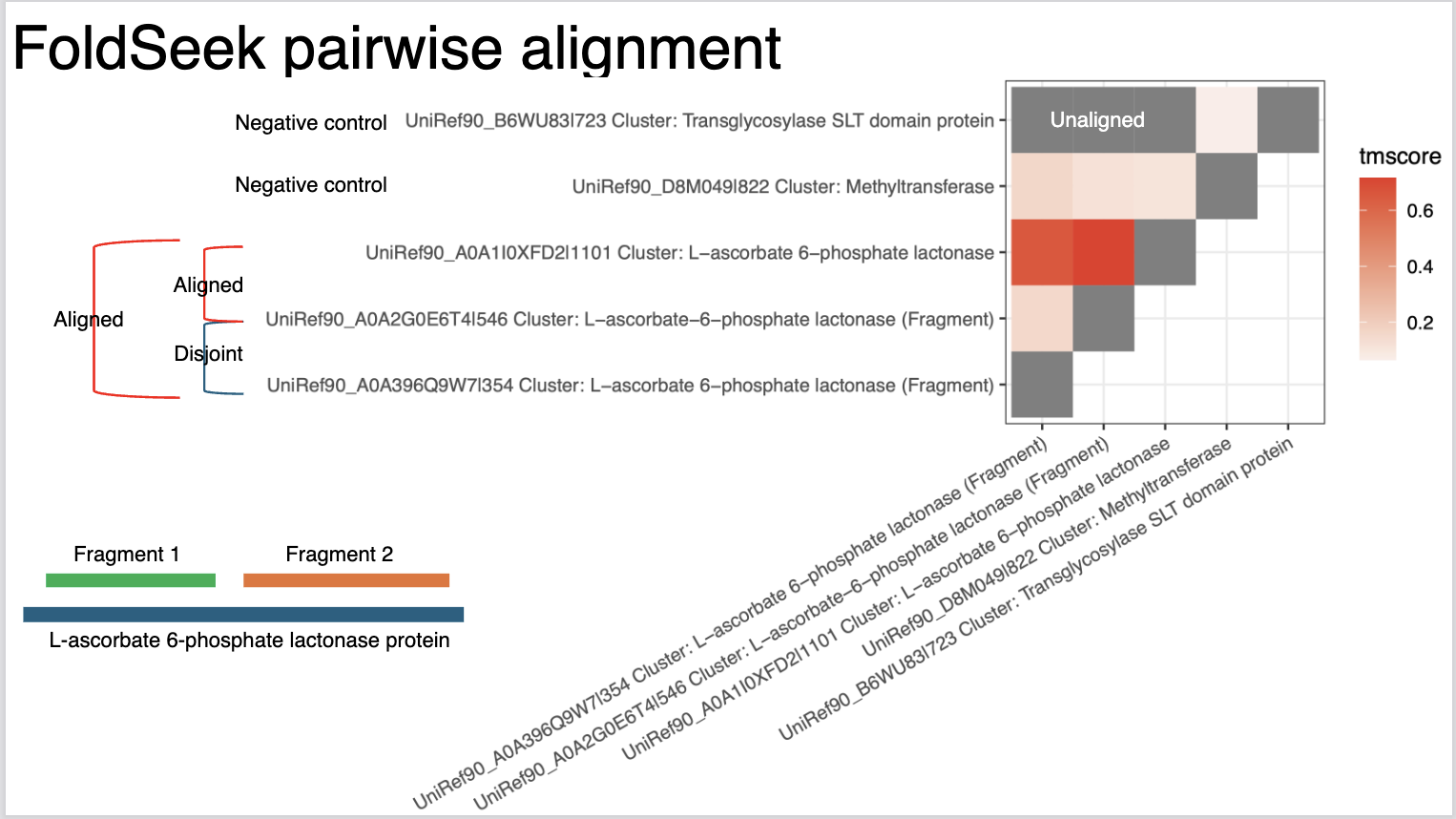
Our pipeline leverages the ESM-2 (3B parameter) model to generate high-dimensional embeddings. This allows us to move beyond rigid structural alignment and capture "fuzzy" semantic similarities.
- Embedding: UniRef90 sequences encoded via ESM-2.
- Dim Reduction: Incremental PCA (2560 → 500 dimensions).
- Graph: k-NN construction ($k=15$) using cosine similarity.
- Clustering: Leiden algorithm optimized for modularity.

3. Next Step: Identifying Disease Clusters
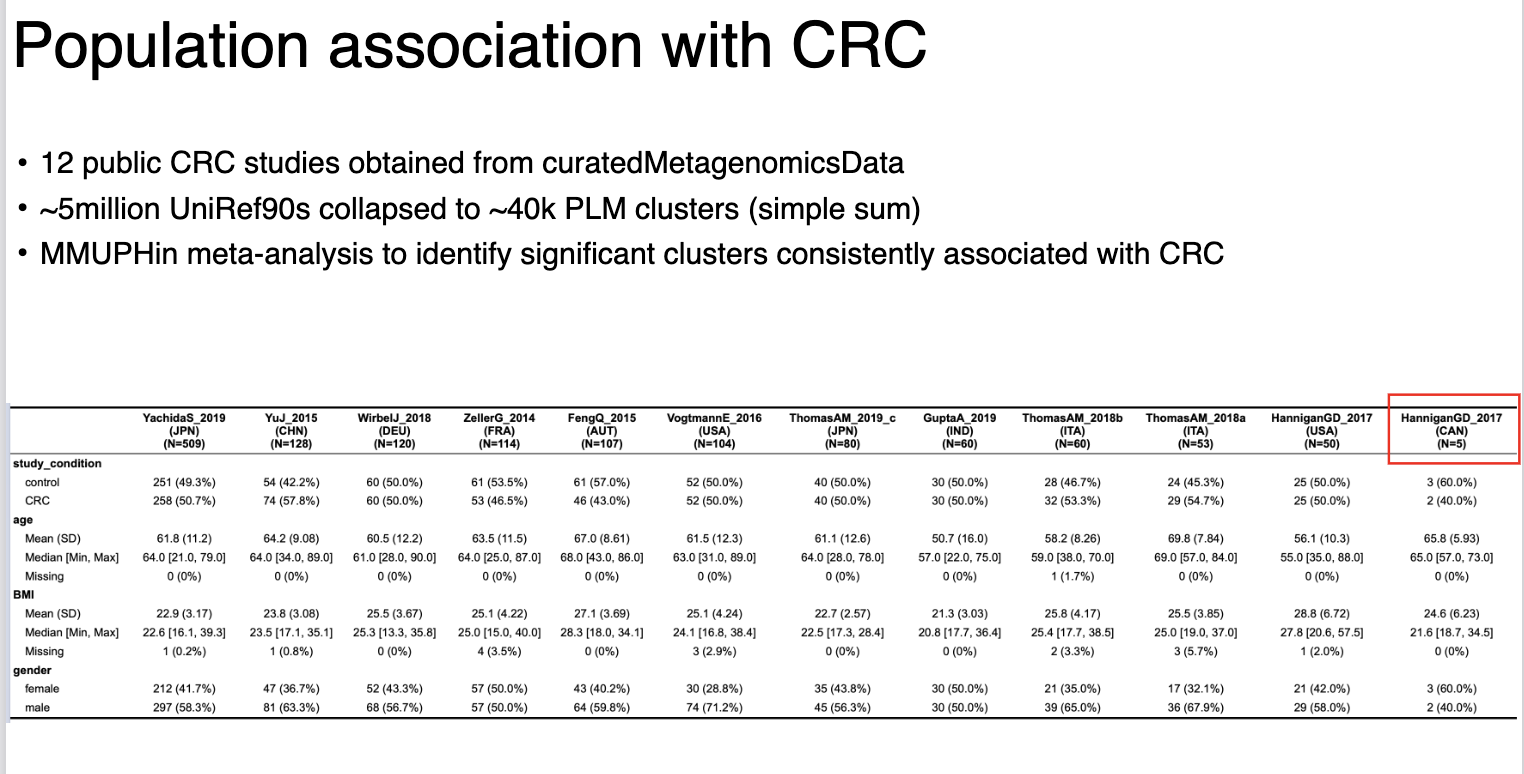
We are currently applying this framework to 785 samples from
curatedMetagenomicData.
Our objective is to recover "Dark Matter" clusters associated with Colorectal Cancer (CRC) and IBD—signals that standard UniRef pipelines likely discard.
1. The Research Question: Democratizing Access?
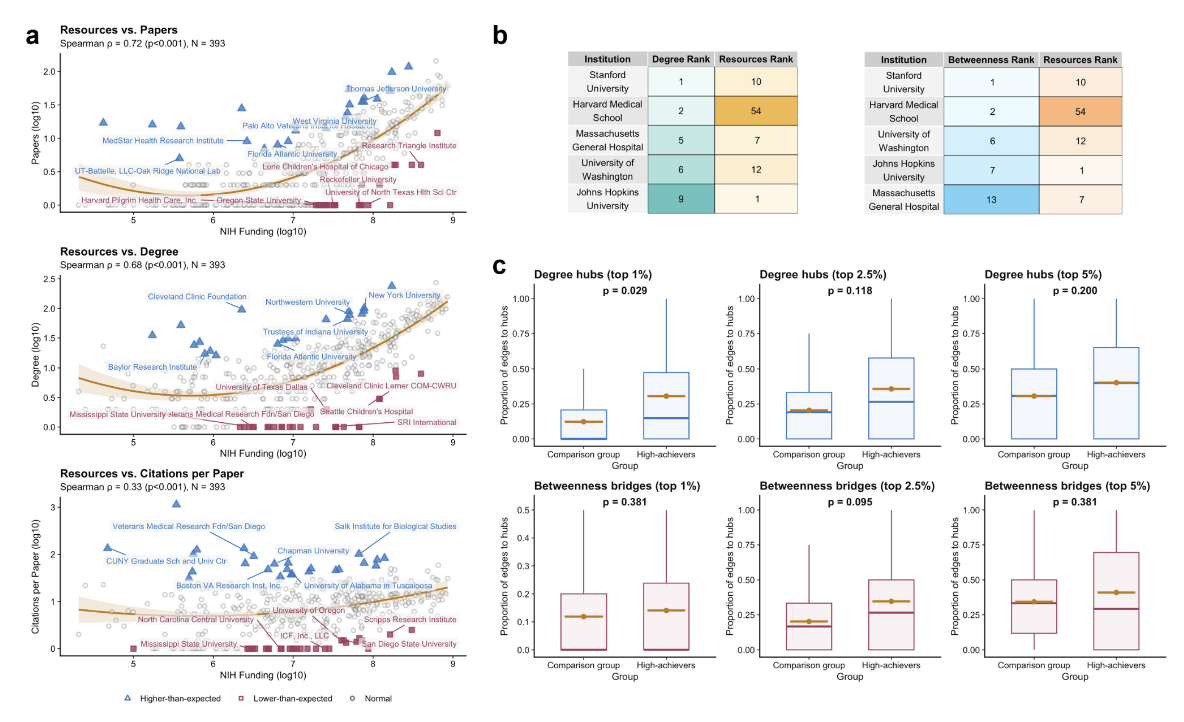
Large Language Models (LLMs) are reshaping biomedical research, but are they democratizing science or reinforcing elite hubs? To answer this, we needed to map the changing landscape of cross-disciplinary collaboration.
We analyzed a corpus of 5,674 Bio-LLM research articles from PubMed to track how institutions and disciplines interact in this emerging field.
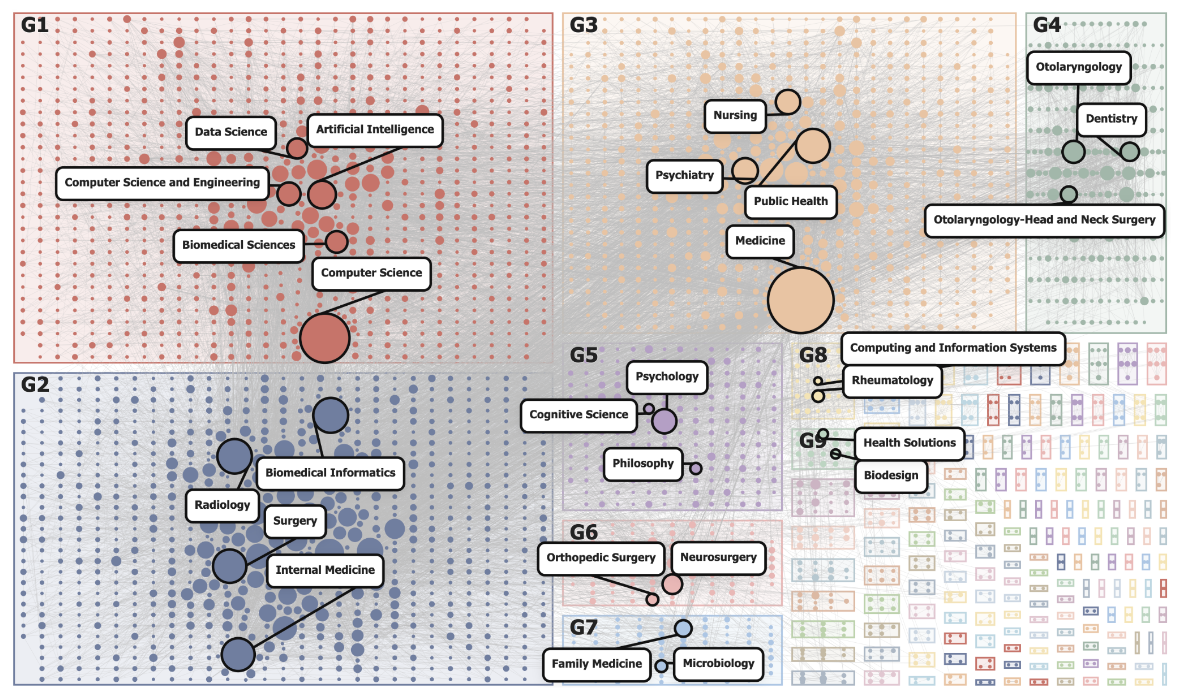
2. The Engineering Bottleneck: Unifying 34k Entities
3. The Discovery: The Collaboration Bonus
This precise entity standardization enabled us to link bibliometric data with NIH funding records. We discovered a quantifiable "Collaboration Bonus": resource-constrained institutions can achieve "elite-tier" impact (citations) by establishing bridging ties with central hubs.
Conclusion: Strategic collaboration effectively allows under-resourced organizations to "borrow" impact, suggesting that LLM research has the potential to be a democratizing force.